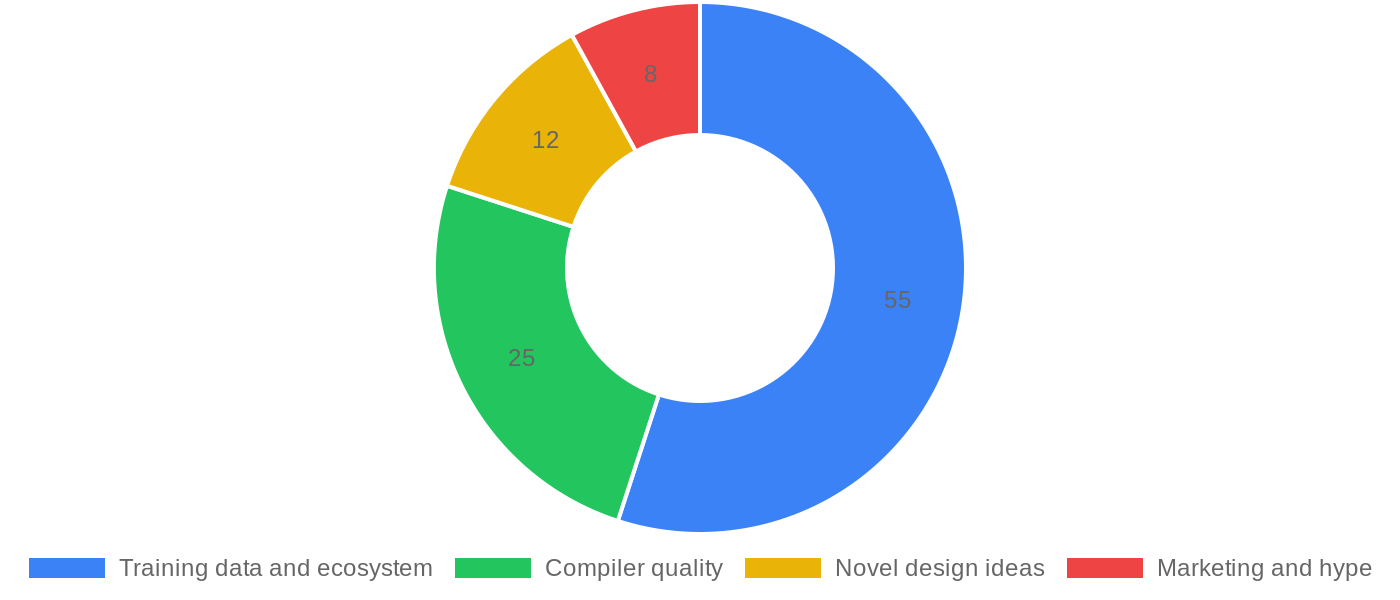
Vercel Labs released Zero on May 15. A systems programming language that compiles to native binaries under 10KB, with a toolchain that emits JSON diagnostics, machine-readable fix plans, and version-matched agent docs. The tagline: “the programming language for agents.”
Four days later, the repo had 4,300 stars. Chris Tate’s announcement post hit 765K views in 24 hours. The discourse was split: either this is the future of human-AI collaboration in systems programming, or it’s a clever marketing experiment riding the agent hype wave.
I fall firmly in the second camp. Not because the idea is bad, but because it solves a problem that doesn’t exist — and introduces a dozen new ones in the process.
What Zero Actually Is
Before the critique, credit where it’s due. Zero makes some genuinely interesting design decisions.
The compiler emits every diagnostic as structured JSON with stable error codes. NAM003 means “unknown identifier” and will mean the same thing in the next version. The zero fix --plan --json command returns a typed fix plan — what file to change, what pattern to replace, how safe the edit is. An agent doesn’t parse human prose; it reads structured data.
Functions use explicit capability-based I/O through a World parameter. If a function writes to stdout, it must accept World in its signature. If it can fail, it must declare raises. Every side effect is prefixed with check. The compiler enforces all of this at compile time.
Builds take ~1ms. Binaries are ~16KB. No GC, no hidden allocator, no implicit async.
Here’s what a Zero program looks like:
pub fun main(world: World) -> Void raises {
check world.out.write("hello from zero\n")
}And here’s what the compiler emits when you make a mistake:
{
"code": "NAM003",
"message": "unknown name `writeln`",
"location": {
"file": "hello.0",
"line": 2,
"column": 11
},
"repair": {
"id": "rename-suggestion",
"candidates": ["write", "writeln_fmt"]
}
}On paper, this sounds like exactly what agentic coding needs: machine-readable errors, deterministic repair metadata, visible effects.
In practice, none of this addresses the actual bottlenecks.
The Problem Zero Claims to Solve
Zero’s premise is that AI agents struggle with traditional compiler output because it’s human prose — natural language error messages that require interpretation. The solution is to emit JSON instead, with stable codes and typed repair metadata that agents can consume directly.
This sounds reasonable until you’ve watched how agents actually interact with compilers.
I’ve been using Claude Code, Cursor, and Aider for months across Rust, Go, C, and Zig codebases. The compiler interaction pattern is never “agent reads error message and fails to parse it.” The agent calls the compiler, gets the error, and the LLM reasons about it — exactly the same way a human engineer does. The prose in a Rust compiler error like error[E0382]: borrow of moved value is not a parsing problem for a language model. It’s input to a reasoning step that determines which variable owns the value, where the move happened, and what the fix is.
Here’s what that interaction looks like in practice — the agent loop that every coding tool uses:
# Simplified agent loop — same pattern in Claude Code, Cursor, Aider
def agent_loop(task: str):
context = gather_context(task)
while not task_complete:
# Step 1: Model reasons about the problem
response = llm_reason(context)
# Step 2: If model wants to act, run the tool
if response.has_tool_call():
result = execute_tool(response.tool_call)
context.append(result) # ← compiler error goes here
# Step 3: Model reads the result and adapts
# The error format (JSON vs prose) is ~1% of this step
continue
# Step 4: No more tool calls = task complete
breakThe bottleneck in this loop is not error message format. It never has been.
The bottleneck is context window size, multi-step planning reliability, tool use accuracy, and hallucination. Agents fail because they lose track of which file they edited, apply changes to the wrong function, produce syntactically correct code with semantically wrong logic, or spin in loops retrying the same failed approach. These are not problems that stable error codes fix.
Agent Loop (shared by Claude Code, Cursor, Aider)
The diagram above shows the architecture shared by every production coding agent in 2026. The loop is: assemble context → call model → execute tools → observe results → repeat. The compiler error format is one input among dozens. The hard problems are context management, permission gating, and sub-agent coordination — none of which Zero addresses.
The JSON Diagnostics Argument Is Weaker Than It Sounds
The claim that agents need structured JSON output assumes that LLMs are bad at parsing text. The evidence says otherwise.
Modern LLMs operate on tokens, not abstract syntax trees. A Rust error formatted as prose is just a sequence of tokens that the model has seen millions of times during training. The model doesn’t “parse” the error — it recognizes the pattern. error[E0382] is already a stable code in practice, even though it’s mixed with prose. The prose following it is additional context the model uses to understand the specific instance.
Rust’s compiler has supported --error-format=json for years. Here’s what that looks like:
$ rustc --error-format=json src/main.rs 2>&1 | head -c 500{
"message": "cannot borrow `x` as mutable more than once at a time",
"code": "E0499",
"level": "error",
"spans": [{
"file_name": "src/main.rs",
"line_start": 5,
"line_end": 5,
"column_start": 5,
"column_end": 10
}],
"children": [],
"rendered": "error[E0499]: cannot borrow..."
}Clang has -fdiagnostics-format=json. Go has staticcheck. If structured compiler output were the unlock for agent reliability, these existing tools would already demonstrate the effect — and they haven’t, because format was never the bottleneck.
Here’s a comparison of what factors actually limit agent reliability vs. what Zero changes:
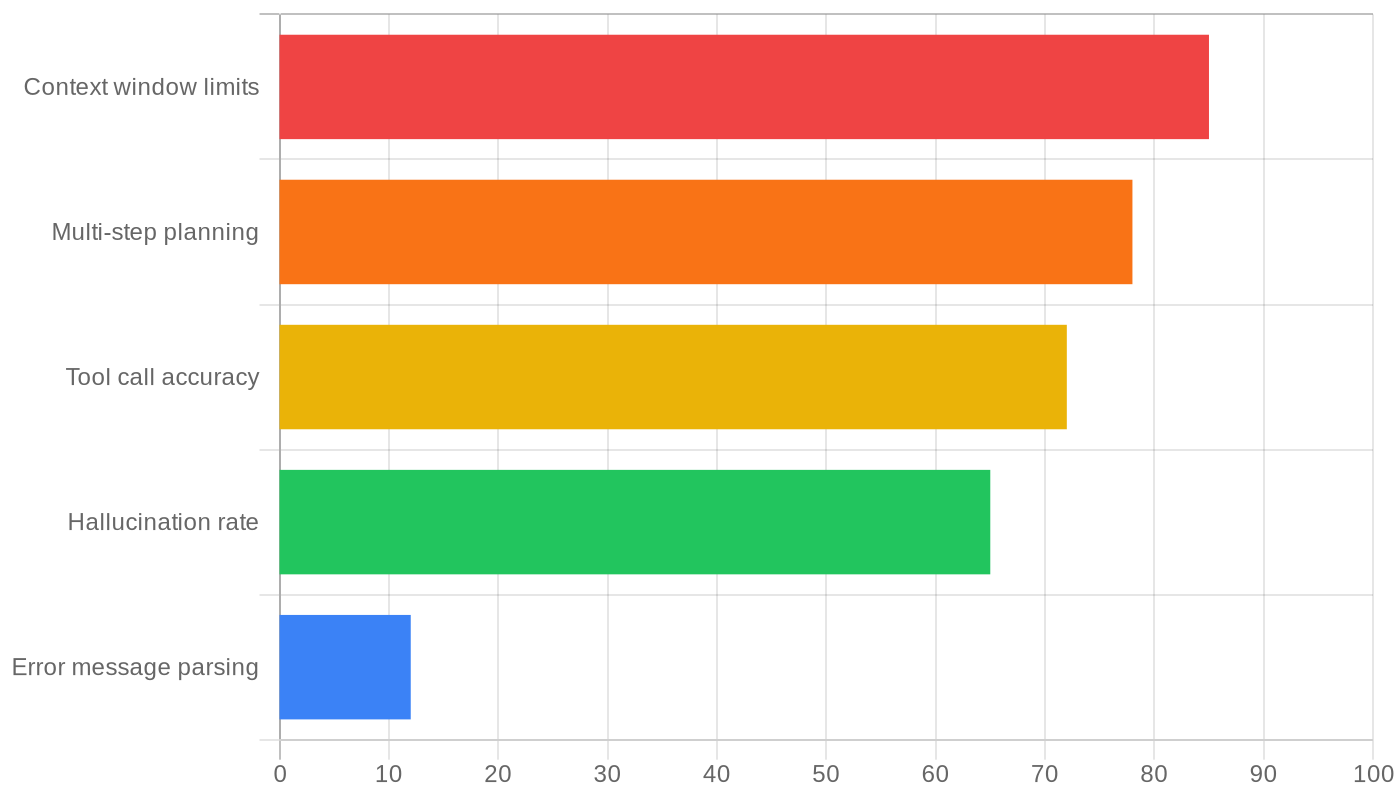
Zero’s value proposition optimizes for the blue bar — the one that accounts for roughly 12% of agent failures. The four red/yellow bars (context, planning, tool use, hallucination) are untouched.
The Training Data Problem Nobody Is Talking About
Here’s the real killer: Zero has no training data.
Every LLM powering today’s coding agents — Claude, GPT-4, Gemini — has been trained on millions of Rust, Python, JavaScript, Go, and C repositories. The models have seen hundreds of thousands of compiler error dialogues: a human writes buggy code, the compiler emits an error, the human reads the error message and fixes the code. These patterns are deeply embedded in the model weights.
An agent using Zero cannot draw on any of that. Every error, every fix pattern, every idiomatic code pattern has to be learned from scratch — from the documentation packaged in zero skills get zero --full, which is itself a few thousand words of markdown.
Let me quantify what I mean. Here’s a rough comparison of ecosystem size for languages an agent might use:
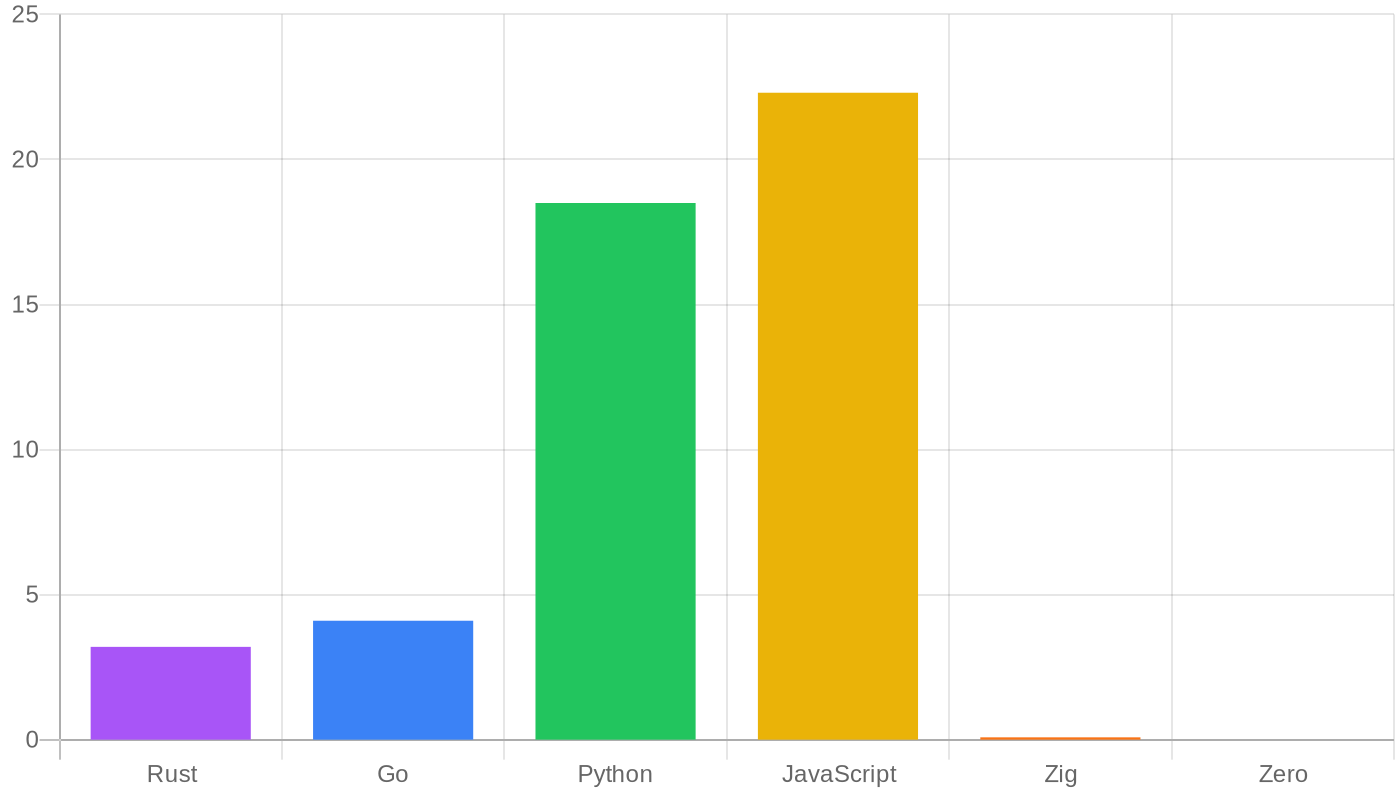
Zero has 4 repositories on GitHub as of May 24. That’s not a typo. The language itself, the docs site, a VS Code extension, and a playground. The total amount of Zero code in LLM training corpora is effectively zero (pun intended again). When an agent needs to write a Zero program that reads a file, parses JSON, and writes to stdout, it cannot draw on any learned pattern — it has to reason from first principles using the documentation strings bundled in zero skills.
Proponents argue that structured data is a better interface than training data. I disagree. The model doesn’t need to parse error messages — it needs to recognize the pattern of the bug and the fix. That recognition comes from training data volume, not error message format. A stable JSON error code is useless if the model has never seen a fix for that code.
This bootstrapping problem is existential for a language whose entire value proposition is “better for AI agents.” The agents aren’t better because the errors are JSON. They’re better when the model understands the language, the library patterns, and the common failure modes — all of which require either massive training data or years of adoption.
The Capability System Is Dependency Injection With Extra Steps
Zero’s World parameter is presented as a breakthrough in explicit effects — a capability-based I/O system that makes side effects visible at the type level.
// Zero's approach — World as a capability token
pub fun read_config(world: World) -> String raises {
// Can do anything — filesystem, network, stdout, env
let content = world.fs.read("config.json")
check content
}
// What does this function actually do? Unknown.
// World bundles every possible side effect into one token.Compare this with a proper effect-typed system. In Koka, every function signature declares exactly which effects it uses:
// Koka's approach — fine-grained effect rows
fun read-config() : <console, fs, exn> string
// Clearly: reads filesystem, writes console, can throw exceptions
val content = read-text-file("config.json")
println("loaded config")
contentThe PL theory community has been working on real capability systems for decades. Pony has reference capabilities that enforce isolation at the type level. Koka has algebraic effect handlers with effect-typed signatures. Haskell’s IO monad provides sequencing guarantees. Zero’s World is closer to passing main(argc, argv, envp) in C with a checked exception annotation bolted on.
A GitHub issue filed against Zero on May 18 (issue #72) documents the problem in detail. The author, who clearly understands capability-based security, identifies four properties that real capability systems require and Zero lacks:
- Effect-typed signatures —
raisesis a boolean, carrying zero information about what effects - Substructural discipline —
Worldis a plain record, storable in globals, duplicable, aliasable - Sequencing/handler structure — no monadic bind, no algebraic-effect handler boundary
- Attenuation algebra — no way to derive a restricted sub-capability
What remains is closer to Unix main(argc, argv, envp) with checked exceptions — a pattern we’ve known for 50 years and deliberately moved away from in systems languages.
For a language built for agents, this matters. An agent reading fun foo(world: World) -> Void raises knows nothing about what foo actually does. It could format the filesystem or print “hello.” The capability is too coarse to reason about statically — which is the entire point of having capabilities in the first place.
The Zero team acknowledges this. Their public roadmap includes fine-grained capabilities (v0.3), substructural discipline (v0.4), and effect handlers (v0.5). Those are the right designs. They’re also not in the language today, and v0.5 is many months away for a project that’s been alive for 9 days.
The Compiler Quality Gap
I want to be careful here because criticizing an experimental v0.1.1 project for not being production-ready is cheap. But Zero’s pitch is that its toolchain is better for agents — more reliable, more deterministic, more structured. The implementation needs to support that claim.
A junior CS student published a public audit of Zero’s native compiler (issue #68). The findings are worth reading in full, but here’s a summary:
// Zero's native compiler — types as string pointers
// This is not a joke. The type checker uses char* for type representation.
typedef struct Type {
char* name; // "i32", "string", whatever
char* kind; // "primitive", "struct", "generic_instance"
// No AST. No algebraic data types. Stringly-typed.
} Type;Generic instantiation is done by string concatenation of source text — finding angle brackets and splicing strings together:
// Zero's generic instantiation — string concatenation
// A C++ template is more type-safe than Zero's "generic" system
char* instantiate_generic(char* base_type, char* param) {
char* result = malloc(strlen(base_type) + strlen(param) + 3);
sprintf(result, "%s<%s>", base_type, param); // String concatenation = type system
return result;
}The borrow checker deep-copies every binding across the entire scope at every if/while branch — essentially snapshotting the entire program state every time control flow diverges, instead of tracking lifetimes:
// Zero's borrow checker — brute force, not analysis
void branch_checkpoint(Scope* scope) {
// Deep-copy EVERY binding in scope at every branch
// This is O(n) memory per branch, not O(1) like proper NLL
for (int i = 0; i < scope->binding_count; i++) {
clone_binding(scope, i); // Snapshot everything
}
}The audit calls it “a patchwork of AI-generated fragments pretending to be design.” That’s harsh, but the technical substance is hard to dismiss. The compiler outright fails on programs that any undergraduate compiler course would handle in week 3.
This is what a v0.1 that an LLM helped write looks like when promises outpace delivery. It’s not wrong in a way that can be fixed with more engineering. The stringly-typed type representation and string-concatenation generics require a fundamental rewrite — which is exactly what the “compiler-zero” directory (the promised Rust rewrite) is supposed to be. But that rewrite isn’t done, and when it ships, it will reset the quality baseline back to zero.
An agent that relies on Zero’s diagnostics today is relying on a compiler whose type system and borrow checker are known to be unsound. The structured JSON output is accurate only to the extent that the compiler correctly analyzes the program. If the compiler can’t correctly analyze programs — and the evidence suggests it can’t — the diagnostics are actively misleading.
The Sub-Agent Argument
Some defenders of Zero argue that the real benefit is for autonomous sub-agents — spawned by a parent agent to work on isolated tasks — where deterministic structured output matters more because there’s no human in the loop to interpret prose.
This is the strongest argument for Zero, and it deserves a real response.
Sub-agent isolation is a real problem. When a parent agent spawns a sub-agent to “check this file for bugs and fix them,” the sub-agent operates with limited context and no human supervision. Structured compiler output could theoretically help it make better decisions with fewer tokens.
But the same objections apply: the bottleneck is reasoning, not parsing. A sub-agent with a 4K context window doesn’t fail because it misreads a Rust error message. It fails because it doesn’t have enough context to understand the codebase it’s modifying, or because it makes the wrong architectural decision with limited information.
Zero’s JSON errors don’t give the sub-agent more context. They don’t help it understand the codebase. They don’t prevent it from applying a syntactically correct but semantically wrong fix. The sub-agent’s problem is the same as the parent agent’s: limited reasoning capacity and limited context.
Why This Won’t Matter
I said “it won’t be anything more than a PoC as we compile directly to machine code and we don’t need another layer of abstraction for this.” Let me unpack that directly.
We compile to machine code. That’s the end of the pipeline. The abstraction between a human/agent writing code and machine code is the compiler toolchain. That toolchain already exists for Rust, Go, C, and Zig. All of them have functional production-quality compilers with rich error output. Zero doesn’t change the compilation target — it changes the surface language and the CLI output format. The output format is not the bottleneck. Adding a new language means adding a new compiler that has to match decades of engineering effort in Rust, LLVM, and GCC. For what — so error messages are JSON instead of prose? Rust already does JSON errors.
The agent loop problem is reasoning, not parsing. Every production coding agent implements a think-act-observe loop. The model proposes an edit, executes it, reads the result, and iterates. The compiler error is one observation among many. Agents don’t fail because they misread error messages. They fail because they lose state, apply changes to the wrong scope, or generate semantically incorrect code that passes the type checker.
# The real failure modes of coding agents — none are "can't parse error"
# Failure mode 1: Context drift
def fix_deadlock(codebase):
edit_file("src/locks.rs", old, new) # Agent fixes the wrong mutex
# The parent context is 70% full of tool output
# Agent hallucinates a function name from an earlier turn
fix_compilation("src/nonexistent.rs") # 💥
# Failure mode 2: Semantically wrong, syntactically correct
def fix_bounds_check(codebase):
# Compiler says "index out of bounds"
# Agent changes: vec[i] → vec.get(i).unwrap()
# Correct syntax, passes type checker, still panics at runtime
# Zero's JSON doesn't help here
apply_patch("src/buffer.rs", "vec[i]", "vec.get(i).unwrap()")
# Failure mode 3: Correct fix, wrong location
def fix_allocation(codebase):
error = compile("src/main.rs")
# "allocation failed" at line 42
# Agent applies fix to line 42 of main.rs
# The actual bug is in src/allocator.rs — line 42 of main.rs is just the call site
# Zero's structured repair plan would make the same mistake
# because it's a semantic misunderstanding, not a format problemNew languages don’t bootstrap ecosystem effects overnight. A language’s value to agents is proportional to the volume of training data available. Rust has millions of repos, thousands of library patterns, and billions of tokens of error-fix dialogues in training corpora. Zero has a few thousand lines of documentation. The JSON error format does not compensate for this deficit.
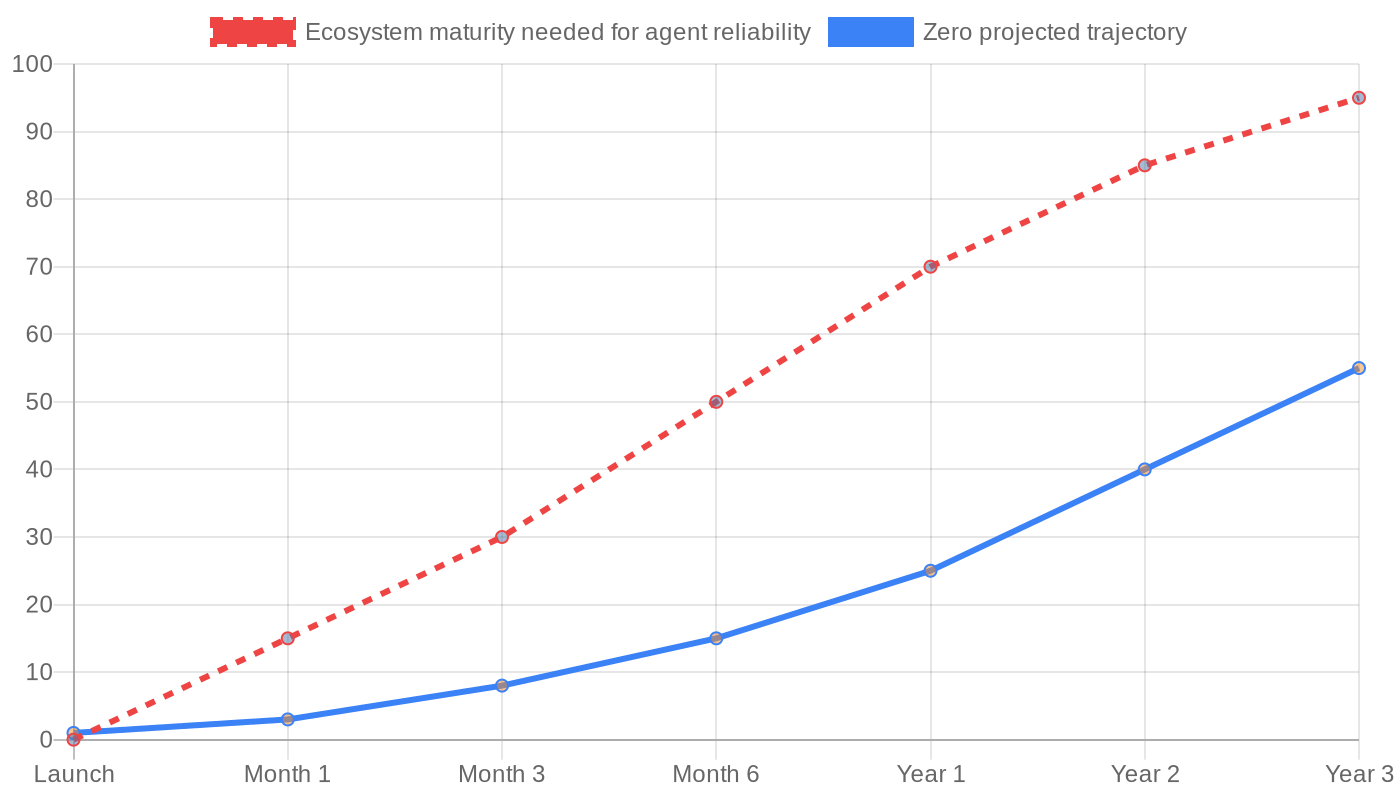
The red dashed line is the ecosystem maturity needed for an agent to reliably work in a language — millions of training examples, thousands of library patterns, stable documentation. The blue line is Zero’s realistic trajectory. It’ll take years to cross that threshold, if it ever does.
Zero’s compiler quality is not agent-grade. The reliability argument for Zero assumes the compiler is correct. The evidence says it isn’t. An agent relying on Zero’s diagnostics is building on an unsound foundation. A structured error from a broken compiler is worse than a prose error from a correct one.
What Zero Gets Right
None of this means Zero is a bad experiment. It’s exactly the right kind of experiment to run: try a radically different design assumption and see what breaks.
The zero skills command is genuinely interesting — version-matched agent documentation bundled with the compiler is a good idea that other ecosystems should adopt. The stable error code scheme is a reasonable design goal, even if its impact on agent reliability is overstated.
The unified CLI design (zero check, zero run, zero build, zero fix, zero explain as subcommands of one binary) is a genuinely good UX pattern. Agents don’t need to reason about which tool to invoke. One binary, one --json flag, consistent output everywhere.
These are ideas that should — and probably will — be adopted by existing language toolchains. Rust’s cargo, Go’s toolchain, and Zig’s build system could all benefit from a unified --json output mode with stable diagnostic codes and machine-readable fix metadata. The key insight isn’t that agents need a new language. It’s that existing toolchains could serve agents better with structured output.
Conclusion
Zero assumes agents need a different programming language to be effective. What agents actually need is better reasoning infrastructure — longer context windows, more reliable tool use, better state tracking — applied to the ecosystems that already exist. Rust’s --error-format=json and Clang’s serialized diagnostics already deliver machine-readable output. What nobody has built is the harness that makes that output actionable inside an agent loop without hallucination.
That’s the real engineering problem. A new language — with a broken compiler, no ecosystem, and no training data — is a distraction from solving it.